Betrouwbaarheidsinterval
Wat is betrouwbaarheidsinterval:
Het is een schatting van een bereik dat in de statistieken wordt gebruikt en dat een populatieparameter bevat. Deze onbekende populatieparameter wordt gevonden via een voorbeeldmodel dat is berekend op basis van de verzamelde gegevens .
Voorbeeld: het gemiddelde van een verzamelde steekproef x̅ kan al dan niet overeenkomen met het werkelijke populatiegemiddelde μ. Hiervoor is het mogelijk om een reeks steekproefgemiddelden te overwegen waarbij dit populatiegemiddelde kan worden ingeperkt. Hoe langer dit interval, hoe groter de kans dat dit optreedt.
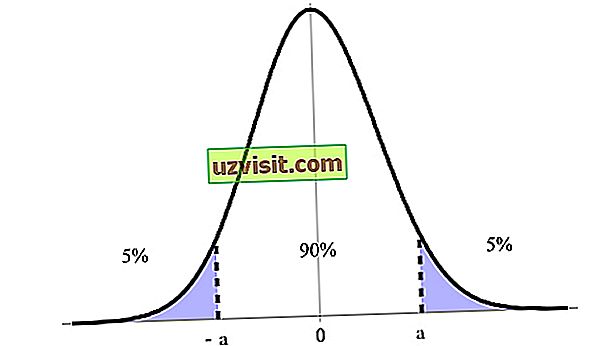
Het betrouwbaarheidsinterval wordt uitgedrukt als een percentage, uitgedrukt als betrouwbaarheidsniveau, waarbij 90%, 95% en 99% het meest zijn aangegeven. In de onderstaande afbeelding hebben we bijvoorbeeld een betrouwbaarheidsinterval van 90% tussen de boven- en ondergrenzen (a en -a ).
Het betrouwbaarheidsinterval is een van de belangrijkste concepten binnen hypothesetests in statistieken, omdat het wordt gebruikt als een maat voor onzekerheid. De term werd geïntroduceerd door de Poolse wiskundige en statisticus Jerzy Neyman in 1937.
Wat is de relevantie van een betrouwbaarheidsinterval?
Het betrouwbaarheidsinterval is belangrijk om de onzekerheidsmarge (of onnauwkeurigheid) van een gemaakte berekening aan te geven. Deze berekening gebruikt de studiemonster om de werkelijke grootte van het resultaat in de bronpopulatie te schatten.
De berekening van een betrouwbaarheidsinterval is een strategie die rekening houdt met foutbemonstering. De omvang van de uitkomst van uw onderzoek en uw betrouwbaarheidsinterval kenmerken de veronderstelde waarden voor de oorspronkelijke populatie.
Hoe smaller het betrouwbaarheidsinterval, hoe groter de kans dat het percentage van de onderzoekspopulatie het werkelijke aantal van de bronpopulatie vertegenwoordigt, waardoor meer zekerheid wordt verkregen over de uitkomst van het onderzoeksobject.
Hoe een betrouwbaarheidsinterval interpreteren?
De juiste interpretatie van het betrouwbaarheidsinterval is waarschijnlijk het meest uitdagende aspect van dit statistische concept. Een voorbeeld van de meest gebruikelijke interpretatie van het concept is het volgende:
Er is een waarschijnlijkheid van 95% dat in de toekomst de werkelijke waarde van de populatieparameter (bijv. Het gemiddelde) binnen het bereik X (ondergrens) en Y (bovengrens) valt.
Het betrouwbaarheidsinterval wordt dus als volgt geïnterpreteerd: het is 95% zeker dat het interval tussen X (ondergrens) en Y (bovengrens) de werkelijke waarde van de populatieparameter bevat.
Het zou volkomen onjuist zijn om te stellen dat: er een kans van 95% bestaat dat het interval tussen X (ondergrens) en Y (bovengrens) de reële waarde van de populatieparameter bevat.
De bovenstaande verklaring is de meest voorkomende misvatting over het betrouwbaarheidsinterval. Nadat het statistische bereik is berekend, kan het alleen de populatieparameter bevatten of niet.
De intervallen kunnen echter variëren tussen de steekproeven, terwijl de parameter van de werkelijke populatie hetzelfde is, ongeacht de steekproef.
Daarom kan de betrouwbaarheidsinterval-vertrouwensrelatie alleen worden gemaakt in het geval dat de betrouwbaarheidsintervallen opnieuw worden berekend voor het aantal monsters.
De stappen voor het berekenen van het betrouwbaarheidsinterval
Het bereik wordt berekend met behulp van de volgende stappen:
- Verzamel de voorbeeldgegevens: n ;
- Bereken het steekproefgemiddelde x̅;
- Bepaal of een standaardafwijking van de populatie ( σ ) bekend of onbekend is;
- Als een standaardafwijking van de populatie bekend is, kan een z- punt worden gebruikt voor het bijbehorende betrouwbaarheidsniveau;
- Als een standaarddeviatie van de populatie onbekend is, kunnen we een statistiek t gebruiken voor het bijbehorende betrouwbaarheidsniveau;
- Dus de onder- en bovenlimieten van het betrouwbaarheidsinterval worden gevonden met behulp van de volgende formules:
a) Standaardafwijking van een bekende populatie :
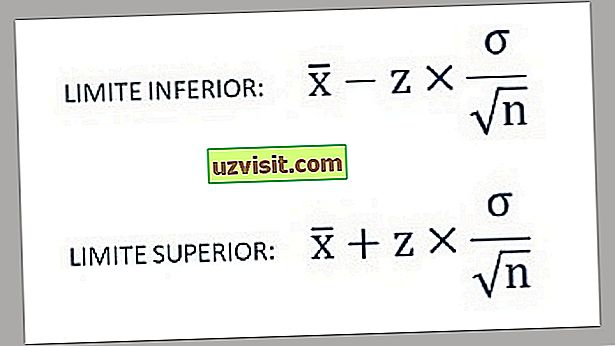
Formule voor het berekenen van de standaardafwijking van een bekende populatie.
b) Standaardafwijking van een onbekende populatie :

Formule voor de berekening van de standaarddeviatie van een onbekende populatie.
Praktijkvoorbeeld van een betrouwbaarheidsinterval
Een klinisch onderzoek evalueerde de associatie tussen de aanwezigheid van astma en het risico op het ontwikkelen van obstructieve slaapapneu bij volwassenen.
Sommige volwassenen werden willekeurig gerekruteerd uit een lijst van overheidsfunctionarissen die gedurende vier jaar moesten worden gevolgd.
Deelnemers met astma, in vergelijking met degenen zonder, hadden een groter risico op het ontwikkelen van apneu in vier jaar.
Bij het uitvoeren van klinisch onderzoek zoals dit voorbeeld, wordt meestal een deel van de populatie van interesse gerekruteerd om de efficiëntie van de studie te verhogen (minder kosten en minder tijd).
Deze subgroep van individuen, de bestudeerde populatie, is samengesteld uit diegenen die voldoen aan de inclusiecriteria en komen overeen om deel te nemen aan het onderzoek, zoals getoond in de afbeelding hieronder.

Vervolgens is de studie voltooid en wordt een effectgrootte (bijvoorbeeld een gemiddeld verschil of een relatief risico ) berekend om de onderzoeksvraag te beantwoorden.
Dit proces, inferentie genaamd, omvat het gebruik van gegevens die zijn verzameld uit de onderzoekspopulatie om de omvang van het daadwerkelijke effect op de populatie van belang, dat wil zeggen de populatie van herkomst, te schatten.
In het gegeven voorbeeld, rekruteerden de onderzoekers een willekeurige steekproef van staatspersoneel (bronpopulatie) die in aanmerking kwamen en stemden ermee in om deel te nemen aan de studie (studiepopulatie) en meldden dat astma het risico op het ontwikkelen van apneu in de studiepopulatie verhoogt.
Om rekening te houden met een steekproeffout als gevolg van de werving van slechts een subgroep van de populatie van belang, berekenden ze ook een betrouwbaarheidsinterval van 95% (rond de schatting) van 1, 06 - 1, 82, wat wijst op een waarschijnlijkheid van 95 % dat het werkelijke relatieve risico in de bronpopulatie tussen 1, 06 en 1, 82 zou zijn .
Betrouwbaarheidsinterval voor gemiddelde
Wanneer men de informatie heeft van de standaardafwijking van een populatie, kan men een betrouwbaarheidsinterval berekenen voor het gemiddelde of het gemiddelde van die populatie.
Wanneer een statistische karakteristiek die wordt gemeten (zoals inkomen, IQ, prijs, lengte, hoeveelheid of gewicht) numeriek is, wordt in de meeste gevallen geschat dat de gemiddelde waarde voor de populatie wordt gevonden.
We proberen dus het populatiegemiddelde ( μ ) te vinden met behulp van een steekproefgemiddelde ( x̅ ), met een foutenmarge. Het resultaat van deze berekening wordt het betrouwbaarheidsinterval voor het populatiegemiddelde genoemd .
Wanneer de standaarddeviatie van de populatie bekend is, is de formule voor een betrouwbaarheidsinterval (CI) voor een populatiegemiddelde:

waarbij:
- x̅ is het steekproefgemiddelde;
- σ is de standaarddeviatie van de populatie;
- n is de steekproefomvang;
- Ζ * vertegenwoordigt de juiste waarde van de standaardnormale verdeling voor uw gewenste betrouwbaarheidsniveau.
Hieronder volgen de waarden voor de verschillende betrouwbaarheidsniveaus ( Ζ * ):
| Niveau van vertrouwen | Waarde van Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (conventioneel) |
| 95% | 1.96 |
| 98% | 02:33 |
| 99% | 02:58 |
De bovenstaande tabel toont z * -waarden voor de verstrekte betrouwbaarheidsniveaus. Merk op dat deze waarden worden verkregen uit de standaard normale verdeling (Z-).
Het gebied tussen elke z * -waarde en het negatieve van deze waarde is het (geschatte) betrouwbaarheidspercentage. Het gebied tussen z * = 1, 28 en z = -1, 28 is bijvoorbeeld ongeveer 0, 80. Daarom kan deze tabel ook worden uitgebreid naar andere betrouwbaarheidspercentages. De tabel toont alleen de meest gebruikte percentages van vertrouwen.
Zie ook de betekenis van hypothese.